
WHAT IS CLARA-DH?
The project will develop a software framework and infrastructure to have easily available all the needed NLP tools and algorithms needed for the scientific work, and finally will decide the inclusion of the new project software developed in an international infrastructure as CLARIN or DARIA or other.
In order to use correctly the project’s infrastructure, it is proposed a project work methodology based on two different stages: First, the exploration and testing of the hypotheses presented for the different approaches and domains to be studied. Secondly, the exploitation of the models developed for their use or visualization of the results via the web framework. It implies thinking in a flexible infrastructure to test our hypothesis and also to ease researches to interact with it when finished. The project will develop a software framework and infrastructure to perform the project tasks with the needed NLP tools and algorithms.
To the development of OERs all the members of the coordinated project involved in the creation of the ORS will share a methodology for developing the resources that will be based on a combination of the User-centered Design (UCD), Universal Design for Learning (UDL), Design 4 All (D4All) principles and accessibility W3C guidelines (2018) to achieve the best level of digital inclusion. All these principles and guidelines are complementary and their focus is that design teams involve users throughout the design process via a variety of research and design techniques, trying to best match their learning needs, aiming to create highly usable and accessible products for them. For instance, UDL offers a framework to work around inclusive approaches to evaluate and determine improvements for the inclusive design in MOOCs at their early stage of development, considering how to design learning environments in a way to develop expert learners, defined as purposeful and motivated, resourceful and knowledgeable, and strategic and goal-directed (CAST, 2014).
Regarding the licensing, resources and courses will be delivered as open learning. This means that such resources can not only be used for free, but are open and with basics of open licensing for the use of open content (Creative Commons). The Creative Commons licensing model allows creators of works to keep their ownership yet at the same time defining under which conditions their work can be openly used.
Table 1 is a summary of the intended type of learning resources, their granularity, their combination and integration in different learning environments and the quality assessment frameworks. Some of the intended resources are: «First steps in HD / creation of corpus for analysis or curation» MOOC; Webinar on the use of the technical infrastructure to be developed and a Webinar on deep machine learning for non computer science researchers.
Table 1. Summary of the proposed learning resources and their different features.
| Type of resources | Granularity | Delivery | Integration | Quality assessment |
| Video recordings | Content Asset | OER repository | MOOC, eBook | Internal Quality Assurance System UNED |
| Radio recordings (audio podcast) | Content Asset | OER repository | MOOC, eBook | Internal Quality Assurance System UNED |
| Webinars | Learning Component | Hybrid learning | Internal Quality Assurance System UNED | |
| eBook | Learning environment | Digital book | UNE71362 Quality of digital educational materials | |
| MOOC | Learning environment | Internet | OpenupED labelling |
One of the most important objectives of the digital humanities is to provide researchers with data and tools to ask new questions in their research and, in turn, help in solving them. One objective of the project is focused on the study of the methods and tools for natural language processing and artificial intelligence (AI) in general, which are applicable in the state-of-the-art to improve the study of cultural heritage.
The domain adaptation techniques using neural networks is proposed to solve the lack of machine learning resources in the field of Digital Humanities. Specifically, the project will focus on textual simplification of sentences and terms that allow a simpler understanding and at the same time a normalization of these terms for their subsequent search and analysis. Within the projects related to natural language processing, deep learning models based on BERT (Devlin, Chang, Lee, & Toutanova, 2018) have become a standard, but the high computing needs of these models make it necessary to use high-capacity infrastructures that contain graphic processing units (GPUs).
Textuall simplification will be carried out converting the more complicated sentences into a version that is easier to understand and normalizing named entities (people, locations, …) through a knowledge base that allows disambiguating the mentions found in the text (Burrows et al., 2020). This task is called entity linking (EL) and it has taken on great importance in the normalization and understanding of the most important entities. Given its many applications in information retrieval, content analysis, data integration and knowledge extraction, numerous works on EL were published during the last decade (Lassner, Baillot, Dogadov, Müller, & Nakajima, 2020; Boros et al., 2020). Main challenges in EL are name variation (several surface forms for one entity), name ambiguity (one surface form for several entities), and absence of the entity in the KB.
Based on our previously experience in the tasks of Named Entity Recognition (Lara-Clares & Garcia-Serrano 2019; Lara-Clares & Garcia-Serrano 2019) and Semantic Indexing (Lara-Clares & Garcia-Serrano 2020) for the Spanish language, our work will be designed and implemented considering the language difficulties, as well as the limited resources in Spanish language.
Our proposed approach will be focused on the sentence-level simplification. The process workflow for simplifying a sentence proposed by this work is shown in Figure 1.
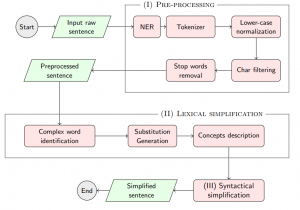
Figure 1. Proposed experimental workflow for preprocessing and sentence simplification
Given a sentence, the preprocessing phase will be divided into four stages as follows: (1.a) named entity recognition of concepts, using different state-of-the-art NER tools for each domain, such as METAMAP (Aronson & Lang 2010) or CTakes (Savova et al. 2010) for the biomedical domain or Stanford CoreNLP (Manning et al. 2014) for the general domain. For the general domain, and for Digital Humanities, we will develop a NER tool according with the DH project corpus; (1.b) tokenize the sentence, using well-known tokenizers, such as the StanfordCoreNLP tokenizer (Manning et al. 2014) for the general domain, BioCNLPTokenizer (Comeau et al. 2014) for the biomedical domain or WordPieceTokenizer (Devlin et al 2019) for BERT-based methods; (1.c) lower-case normalization; (1.d) char filtering, which allows the removal of punctuation marks or special characters; and finally, (1.e) the removal of stop-words.
Once the sentence is preprocessed, the next stage is to perform the lexical simplification of the words and keywords that conforms the sentence. This process can be subdivided in three steps as follows: (a) complex word identification, whose aim is to identify the set of words and phrases that can be candidates for the substitution; (b) substitution generation, whose aim is to rank and substitute the list of candidates with simpler ones; and (c) concept description, whose aim is to add extra information to the sentence for the complex words that cannot be substituted. Our first approach on the complex word identification subtask will make use of pretrained BERT models, such as Spanish-BERT model (Cañete et al. 2020) for general domain and ClinicalBERT (Huang et al. 2019) for biomedical domain, and the fine-tuning technique for training a model that can recognize complex entities in our corpus. The substitution generation will select the simplest candidate for each word or keyphrases by using a set of features for English language and Bott et al. (2012, 2014) for Spanish language, such as the fre-quency of the words and the length of the words, along with specialized word embeddings, such as FastText (Bojanowski et al., 2017), for calculating the semantic similarity of the candidates with the original word or phrase. Finally, it will be applied to syntactic simplification as a tool for Named Entity Recognition(NER), which have been demonstrated to be effective, especially in the medical domain (Jonnalagadda & Gonzalez, 2010). Other methods from a recent survey (Sikka and Mago, 2020) of lexical and syntactic simplification will be considered for this work.
In addition, there will be implemented a front-end Website as a SentenceSimplification tool which will be located in a UNED server, which will integrate the independent modules from Figure 1, allowing the users to personalize the simplification process and post-processing, annotating and extracting the obtained results in different formats.
CLARA-DH RESEARCH TEAM

ANA GARCÍA SERRANO
agarcia@lsi.uned.es

COVADONGA RODRIGO SAN JUAN
covadonga@lsi.uned.es

JOSÉ LUIS DELGADO LEAL
jdelgado@lsi.uned.es

JUAN MANUEL CIGARRÁN RECUERO
juanci@lsi.uned.es

Francisco Iniesto Carrasco
finiesto@lsi.uned.es

ANTONIO MENTA GARUZ
amenta@invi.uned.es

JESÚS CORREA SÁNCHEZ
jescorrea@tudela.uned.es

RICARDO SÁNCHEZ GARCÍA
rgarcia@lsi.uned.es

EVA SÁNCHEZ SALIDO
evasan@lsi.uned.es

VÍCTOR SÁNCHEZ SÁNCHEZ
vsanchez@lsi.uned.es

ANDRÉS RODRÍGUEZ FRANCÉS
arodriguez@Lsi.uned.es
CLARA-DH RESOURCES
PUBLICATIONS
- 2024
- Menta A. and García-Serrano (2024) “Reaching Quality and Efficiency with a Parameter-Efficient Controllable Sentence Simplification Approach”. ComSIS journal (http://www.comsis.org/) ISSN: 1820-0214. In press http://www.comsis.org/archive.php?show=lstnew Forthcoming articles section. JCR 2022: Computer Science, Information systems; JIF: 1.4 Rank by JIF (Journal Impact Factor): Q4 (137/158); Journal Citation Indicator, JCI: 0,36; Rank by JCI: Q3 (180/251); 5 Year Impact factor: 1.2. Open Access. Scimago Journal Rank – SJR 2022: 0,317; Q3; H-index: 28
- 2023
- Sanchez-Salido, A. Menta and García-Serrano (2024) “Seeking Information in Spanish Historical Newspapers: The Case of Diario de Madrid (18th and 19th Centuries)”. DHQ journal. ISSN: 1938-4122. http://digitalhumanities.org/dhq/vol/17/4/000735/000735.html JCR 2022: Humanities, Multidisciplinary; JIF: 0,4 Rank by JIF (Journal Impact Factor); Journal Citation Indicator, JCI: 0,83; Rank by JCI: Q2 (104/409); 5 Year Impact factor: 0,4. Open Access Scimago Journal Rank – SJR 2022: 0,175; Q3; H-index:5
- García-Serrano, Ana; Francisco Paños Merino; César Férnandez Sánchez (2023) “Una mirada digital a los datos: el trabajo de un estudioso de la Antigua Grecia VI” Congreso de la Sociedad Internacional de Humanidades Digitales Hispánicas – HDH 2023 “Encuentros y transformaciones” Logroño, 18 y 19 octubre.
- 2022
- (199) Lara-Clarés, A; Lastra-Diaz, JJ; Garcia-Serrano, A (2022) “A reproducible experimental survey on biomedical sentence similarity: A string-based method sets the state of the art”. PLoS ONE 17(11): e0276539. ISSN: 1932-6203 https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0276539. Publisher: Public Library of Science JCR 2021 Journal Impact Factor, JIF: 3.752; Journal Citation Indicator, JCI: 0.88; Multidisciplinary Sciencies SCIE; Rank by JIF: Q2 (29/74); Rank by JCI: Q1 (28/135). (Science Citation Index Expanded, SCIE) CiteScore 2021: 5.6 CiteScore Tracker 2021: 5.4 CiteScore Rank 2021: Q1 (15/120, Multidisciplinarity) SJR 2021 0.852. https://arxiv.org/abs/2205.08740 submitted 18/05/2022
- (196) Lastra-Diaz, JJ; Lara-Clares, A; Garcia-Serrano, A (2022) “HESML: a real-time semantic measures library for the biomedical domain with a reproducible survey”. BMC Bioinformatics. Springer Nature. ISSN: 1471-2105. Pp: 1-31. DOI: 10.1186/s12859-021-04539-0 https://bmcbioinformatics.biomedcentral.com/articles/10.1186/s12859-021-04539-0 JCR 2021 Journal Impact Factor, JIF: 3.328; Journal Citation Indicator, JCI: 0.82; MATHEMATICAL & COMPUTATIONAL BIOLOGY; Rank by JIF: Q2 (20/55); Rank by JCI: Q2 (21/67). (Science Citation Index Expanded, SCIE) CiteScore 2021: 5.9 CiteScore Tracker 2021: 5.2 CiteScore Rank 2021: Q1 (177/749, CS Comp. Science Applications) SJR 2021 1.246. HIndex: 218
- Garcia Serrano, A.; Menta Garuz A. (2022) “La inteligencia artificial en las Humanidades Digitales: dos experiencias con corpus digitales”. Revista de Humanidades Digitales, v.7, 19-39, ISSN 2531-1786. https://doi.org/10.5944/rhd.vol.7.2022.30928
- Menta, Antonio; Garcia-Serrano, Ana; (2022). “Controllable Sentence Simplification Using Transfer Learning”. Simple Text Task at PAN – CLEF 2022 – Conference and Labs of the Evaluation Forum, Bolonia, Septb. 5-8, 2022. CEUR-WS, vol 3180, pp: 2818-2825. ISSN: 1613-0073. https://ceur-ws.org/Vol-3180/ GGS 2021 Class: 3; Rating: B
- Menta, Antonio; Sanchez-Salido, Eva y Garcia-Serrano, Ana; (2022) “Transcripción de periódicos históricos: aproximación CLARA-HD”. Proceedings of the Annual Conference of the Spanish Association for Natural Language Processing: Projects and Demonstrations (SEPLN-PD 2022). A Coruña, Spain, septb 21-23. CEUR-WS V 3224. pp:70-74. ISSN: 1613-0073 https://ceur-ws.org/Vol-3224/
- Iniesto, F., Rodrigo, C., & Hillaire, G. (2022). “A Case Study to Explore a UDL Evaluation Framework Based on MOOCs”. Applied Sciences, 13(1), 476. https://www.mdpi.com/2076-3417/13/1/476
PUBLIC DISSEMINATION
- 2024
- Ana García Serrano (2024) “Transkribus: herramienta de transcripción de escritura manuscrita e impresa en textos antiguos” ponencia apoyada por el técnico de la UNED Andrés Rodríguez Francés para la parte de trabajo práctico tutorizado. I Jornadas en Humanidades digitales de la facultad de filosofía y Letras de la UAM. 9 y 10 de enero de 2024.
- 2023
- Ana García Serrano (2023) “Experiencias en proyectos de Humanidades Digitales” III seminario de proyectos transdisciplinares en humanidades e informática organizado por el INCIPIT-CSIC, UNAV y URJC. Organizado con una ayuda de la asociación HDH. URJC (Fuenlabrada, Aulario I, aula 105). 1 diciembre 2023. https://www.unav.edu/web/laboratorio-de-humanidades-digitales/actividades/proyectos-transdisciplinares-en-humanidades-e-informatica
- Ana García Serrano (2023) “Proyecto CLARA-HD” Dariah Day BNE 7 de noviembre de 2023. Poster dinámico (2min) presentando el proyecto: Métodos de la lingüística computacional para la legibilidad y simplificación automática en humanidades (PID2020-116001RB-C32). https://www.bne.es/es/agenda/dariah-day-jornadas-sobre-humanidades-digitales-clariah-es https://www.clariah.es/. Disponible en https://m.youtube.com/watch?v=ua5DDvd5MUI
- Ana García Serrano (2023) “Digitalización, lectura y tratamiento de textos en el Diario de Madrid: algunas soluciones desde la inteligencia artificial” En el seminario “Ciudad, vida cotidiana y prensa en España (siglos XVIII-XIX). Nuevos enfoques metodológicos y humanidades digitales” Organizado por Isabel Larriba, AMU-CNRS TELEMMe, y Álvaro Molina (CARCEM – Cartografías de la ciudad en la edad moderna: relatos, imágenes e interpretaciones, PID 2020-113380GB-100/AEI). 17 de marzo, Universidad Aix-Marseille, Aix-en-Provence, Francia.
- 2022
- Ana García Serrano (2022) “Una aproximación a las Humanidades Digitales” Presentación invitada en la Conferencia Libraries and Digital Humanities: Projects and Challenges, UNED y Cuartel de Conde Duque Madrid 13-16 septiembre 2022. Disponible (en español) en https://www.youtube.com/watch?v=-wK94BWP-0o&list=PLLxGBNWsqtEAKpIkHvAEFjUGh90VKSbQW&index=12
- Ana García-Serrano, Antonio Menta and Eva Sánchez-Salido (2022) “Digital Humanities and Text Simplification Tasks: The CLARA-HD Project”. III WS Intele – sesión pósteres. Hotel AIRE GRAN HOTEL COLON, Madrid, 13-14 septb. https://ixa2.si.ehu.eus/intele/posters_iii_workshop; https://ixa2.si.ehu.eus/intele/node/126
- Covadonga Rodrigo San Juan, Ana García Serrano y Ángeles Sánchez Elvira Paniagua (2022) “Arte, psicología y tecnología: una aproximación multidisciplinar para lograr museos inclusivos. Proyectos Spektrum e Inclusive Heritage”. Parallell session entitled “Proyectos Europeos de Digitalización e Innovación con participación de la UNED. II” WORKSHOP: XII Jornadas de Investigación en Innovación Docente de la UNED Grupo INADOC. 1 de junio 2022. https://canal.uned.es/video/6298901d6f3c002d392cdf00.
OTHER – DEMOS
- Juan Cigarrán, Andrés Rodriguez-Francés, Ana García-Serrano (2024) CLARA-DM corpus: Public Access to CLARA-DM paleographic corpus. Corpus transcribed with TRANSKRIBUS including some historical journals from Diario de Madrid available at “Hemeroteca de la BNE”.
OTHER – OPEN SOFTWARE
- Sánchez Salido, E. y García Serrano. Recursos informáticos en abierto (2023). Modelo de transcripción automática «paleográfica» de textos del siglo XVIII y XIX del Diario de Madrid (BNE), que se puede descargar desde la website de la herramienta TRANSKRIBUS https://readcoop.eu/model/spanish-print-xviii-xix.
- Antonio Menta (2023) Python framework for testing different models and datasets. It facilitates the reproducibility of the experiments performed and allows the comparison between the results obtained with different hyperparameters. Model trained using Pytorch-lightning and HuggingFace on an Nvidia GeForce GTX 1070 Ti GPU with 8 GB of memory. https://github.com/Hisarlik/Simplification_experiments
- Lara-Clares, A.; Lastra-Díaz, J J.; Garcia-Serrano, A. 2022, «HESML V2R1 Java software library of semantic similarity measures for the biomedical domain«, https://doi.org/10.21950/AQLSMV, e-cienciaDatos.
OTHER – DATASETS


